데이터 마트
제1장 R 기초와 데이터 마트
목차
1. 데이터 마트의 이해
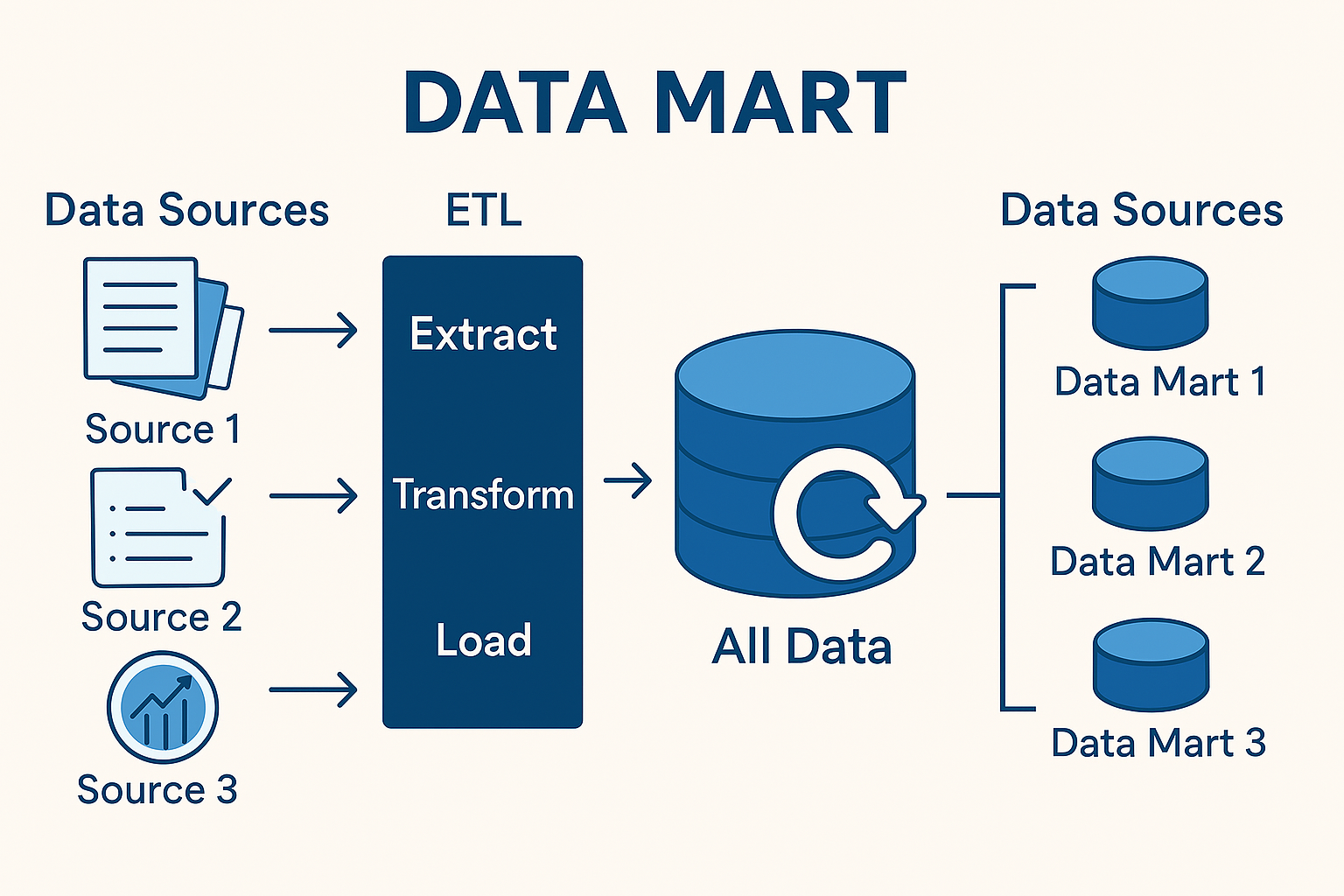
데이터 마트(Data Mart)란?
효율적인 데이터 분석을 위해서는 데이터를 체계적으로 준비할 필요가 있습니다. 따라서 데이터 분석을 하기에 앞서 분석 목적에 맞춰 데이터를 수집, 변형하는 과정이 필요합니다. 데이터 마트란 데이터 웨어하우스로부터 특정 사용자가 관심을 갖는 데이터들을 주제별(예: 고객분석, 제품 판매), 부서별(예: 마케팅, 영업)로 추출하여 사용 목적에 따라 가공한 분석 전용 데이터 저장소라 할 수 있습니다. 이렇게 분석 목적별, 주제별, 부서별로 데이터를 수집하고 변형하여 한 곳에 모으는 작업을 데이터 마트 개발이라 부릅니다. 효율적인 데이터 마트 개발을 위하여 R에서 제공하는 reshape, sqldf, plyr 등의 다양한 패키지를 활용할 수 있습니다.
- 데이터 웨어하우스: 전사적 통합 데이터 저장소
- 데이터 마트: 부서별/주제별 목적에 맞춘 분석 단위 저장소
데이터 전처리(Data Preprocessing)
데이터 마트에 사용자가 원하는 데이터를 수집하고 변형하여 적재했다면(데이터 마트를 개발했다면), 이제 전처리 단계를 거쳐야 합니다. 빅데이터 분석을 수행하기 전에 데이터를 전처리는 필수적인 단계입니다. 이 과정은 데이터를 정제하고 분석에 적합한 형태로 변환하여, 모델의 정확성과 신뢰성을 높이는데 기여합니다. 데이터 정제 과정은 크게 결측값과 이상값을 처리로 이루어지며, 분석 변수 처리 과정은 데이터 분석에 맞게 데이터셋의 변수 선택, 차원 축소, 파생변수 생성, 변수 변환, 클래스 불균형 처리 등의 작업을 수행합니다.
데이터 정제(Data Clearning)::
결측값(Missing Values) 처리: 데이터셋에서 누락된 값을 식별하고 적절한 방법으로 대체하거나 제거합니다. 예를 들어, 평균 또는 중앙값으로 대체하거나 해당 행을 삭제할 수 있습니다....elt
이상값(Outliers) 처리: 다른 데이터와 현저히 차이나는 값을 탐지하고, 이를 수정하거나 제거하여 분석의 왜곡을 방지합니다.
분석 변수 처리(Feature Engineering):
변수 선택(Feature Selection): 분석에 중요한 변수를 선태하여 모델의 복잡성을 줄이고 성능을 향상시킵니다.
차원 축소(Dimensionality Reduction): 주성분 분석(PCA)과 같은 기법을 사용하여 변수의 수를 줄여 계산 효율성을 높입니다.
파생변수 생성(Derived Variables): 기존 변수를 조합하거나 변형하여 새로운 변수를 생성합니다.
변수 변환(Variable Transformation): 변수의 스케일을 조정하거나 로그 변환 등을 통해 데이터의 분포를 조정합니다.
클래스 불균형 처리(Class Imbalance Handling): 오버샘플링이나 언더샘플링 등의 기법을 사용하여 클래스 간의 균형을 맞춥니다.
요약변수와 파생변수
요약변수(Summary Variables): 요약 변수는 기존의 원시 데이터를 집계하거나 통계적으로 요약하여 만든 변수입니다. 보통 편균, 합계, 빈도, 비율 등의 수치로 표현되며, 사용자의 일반적인 행동 패턴이나 성향을 파악하는 데 유용하게 사용됩니다. 이는 변수의 재활용성과 범용성이 높으며, 다양한 분석에 기초 지표로 활용됩니다. 예를 들어, 아마존(Amazon)은 고객의 지난 6개월 동안의 총 주문 건수를 total_orders_last_6_monts라는 요약변수로 집계하여 고객의 구매 빈도를 파악합니다.
파생변수(Derived Variables): 파생변수는 기본 통계 변수와는 달리, 특정한 목적과 조건을 바탕으로 데이터를 새롭게 조합하여 만든 변수입니다. 조건부 로직, 시간 조건, 사용자 특성 등을 활용해 만들어지며, 분석 목적에 따라 매우 구체적이고 전략적인 변수가 됩니다 하지만, 주관적 개입이 들어갈 수 있기 때문에, 논리적 타당성을 확보하는 것이 중요합니다. 예를 들어, 넷플릭스(Netfilx)는 일정 시간 이상 연속으로 콘텐츠를 시청한 사용자를 식별해 binge_watcher라는 파생변수를 생성합니다. 이 변수는 콘텐츠 소비 성향을 기반으로 추천 알고리즘을 개선하는 데 활용됩니다.
2. 데이터 마트 개발을 위한 R 패키지 활용
reshpae 패키지
reshape 패키지는 20개에 가까운 함수들을 보유하고 있으며, 데이터 마트를 개발하는 데 강력한 melt와 cast라는 두 개의 함수가 있습니다. 이 패키지에 포함된 함수와 활용법은 R reshape 공식 문서에서 확인할 수 있습니다.
-
melt(): 이 함수는 데이터를 특정 변수를 기준으로 녹여 나머지 변수들을 세분화된 long format 형태로 변환합니다. 예를 들어, 다음과 같이 데이터셋을 생성하고 melt() 함수를 적용할 수 있습니다:
# Create DataFrame
score <- data.frame(
student_number = c(1, 2, 1, 2),
semester = c(1, 1, 2, 2),
math_score = c(60, 90, 70, 90),
english_score = c(80, 70, 40, 60)
)
score
| student_number | semester | math_score | english_score |
|---|---|---|---|
|
|
|
|
|
| 1 | 1 | 60 | 80 |
| 2 | 1 | 90 | 70 |
| 1 | 2 | 70 | 40 |
| 2 | 2 | 90 | 60 |
library(reshape2)
long_format <- melt(score, id = c("student_number", "semester"))
long_format
| student_number | semester | variable | value |
|---|---|---|---|
|
|
|
|
|
| 1 | 1 | math_score | 60 |
| 2 | 1 | math_score | 90 |
| 1 | 2 | math_score | 70 |
| 2 | 2 | math_score | 90 |
| 1 | 1 | english_score | 80 |
| 2 | 1 | english_score | 70 |
| 1 | 2 | english_score | 40 |
| 2 | 2 | english_score | 60 |
-
dcast(): long format의 데이터를 wide format으로 변환합니다. 즉, 여러 행에 걸쳐 있는 데이터를 하나의 행으로 집계하거나 재구조화할 수 있습니다. 예를 들어, 위에서 만든 long_format 데이터를 다시 원래 형태로 복원하려면 다음과 같이 합니다:
# 학생의 과목별 평균점수
dcast(long_format, student_number ~ variable, mean)
# 학생의 학기별 평균점수
dcast(long_format, student_number ~ semester, mean)
# 학생의 과목별 최댓값
suppressWarnings(
dcast(long_format, student_number ~ variable, function(x) max(x, na.rm = TRUE))
)
| student_number | math_score | english_score |
|---|---|---|
|
|
|
|
| 1 | 65 | 60 |
| 2 | 90 | 65 |
| student_number | 1 | 2 |
|---|---|---|
|
|
|
|
| 1 | 70 | 55 |
| 2 | 80 | 75 |
| student_number | math_score | english_score |
|---|---|---|
|
|
|
|
| 1 | 70 | 80 |
| 2 | 90 | 70 |
sqldf 패키지
sqldf는 표준 SQL 문장을 활용하여 R에서 데이터프레임을 다루는 것을 가능하게 해주는 패키지로서 SAS에서 PROC SQL과 같은 역할을 합니다.
library(sqldf)
sqldf('select * from score')
sqldf('select * from score where student_number = 1')
sqldf('select student_number, avg(math_score), avg(english_score) from score group by student_number')
| student_number | semester | math_score | english_score |
|---|---|---|---|
|
|
|
|
|
| 1 | 1 | 60 | 80 |
| 2 | 1 | 90 | 70 |
| 1 | 2 | 70 | 40 |
| 2 | 2 | 90 | 60 |
| student_number | semester | math_score | english_score |
|---|---|---|---|
|
|
|
|
|
| 1 | 1 | 60 | 80 |
| 1 | 2 | 70 | 40 |
| student_number | avg(math_score) | avg(english_score) |
|---|---|---|
|
|
|
|
| 1 | 65 | 60 |
| 2 | 90 | 65 |
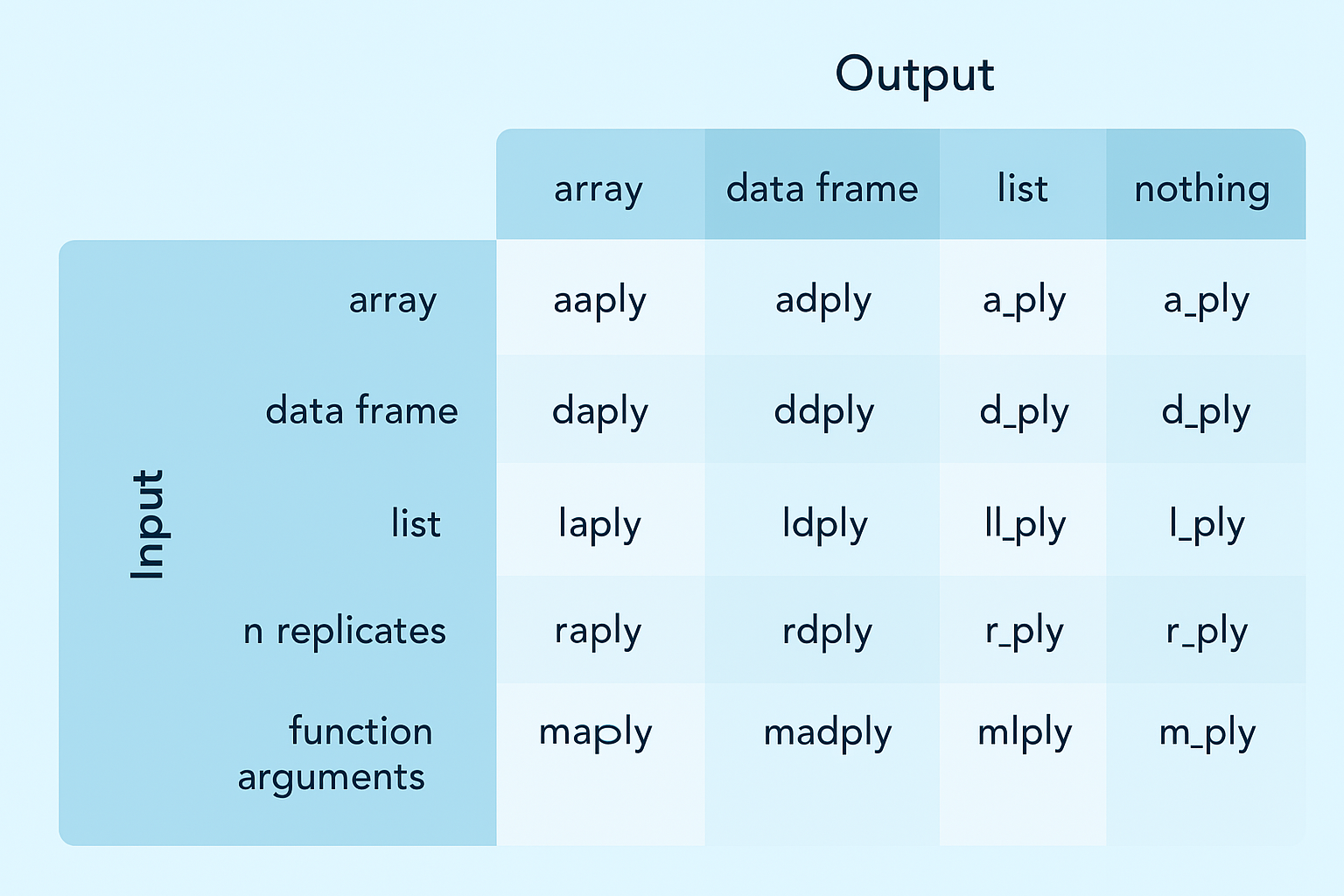
plyr 패키지
plyr은 apply 함수를 기반으로 데이터를 분리하고 다시 결합하는 가장 필수적인 데이터 처리 기능을 제공합니다. plyr은 입력되는 데이터 구조와 출력되는 데이터 구조에 따라 여러 가지 함수를 지원합니다. 이 밖에도 다양한 함수를 제공하지만 그중 ddply 함수는 실제 활용 빈도가 높습니다. 추가적인 내용은 R plyr 공식 문서에서 확인 할 수 있습니다.
score <- data.frame(
class = c('A', 'A', 'B', 'B'),
math = c(50, 70, 60, 90),
english = c(70, 80, 60, 80)
)
score
| class | math | english |
|---|---|---|
|
|
|
|
| A | 50 | 70 |
| A | 70 | 80 |
| B | 60 | 60 |
| B | 90 | 80 |
library(plyr)
# summerise: 데이터 요약,
ddply(score, "class", summarise, math_avg = mean(math), eng_avg = mean(english))
# transform: 기존 데이터에 추가
ddply(score, "class", transform, math_avg = mean(math), eng_avg = mean(english))
| class | math_avg | eng_avg |
|---|---|---|
|
|
|
|
| A | 60 | 75 |
| B | 75 | 70 |
| class | math | english | math_avg | eng_avg |
|---|---|---|---|---|
|
|
|
|
|
|
| A | 50 | 70 | 60 | 75 |
| A | 70 | 80 | 60 | 75 |
| B | 60 | 60 | 75 | 70 |
| B | 90 | 80 | 75 | 70 |
data <- data.frame(
year = c(2012, 2012, 2012, 2012, 2013, 2013, 2013, 2013),
month = c(1, 1, 2, 2, 1, 1, 2, 2),
value = c(3, 5, 7, 9, 1, 5, 4, 6)
)
data
| year | month | value |
|---|---|---|
|
|
|
|
| 2012 | 1 | 3 |
| 2012 | 1 | 5 |
| 2012 | 2 | 7 |
| 2012 | 2 | 9 |
| 2013 | 1 | 1 |
| 2013 | 1 | 5 |
| 2013 | 2 | 4 |
| 2013 | 2 | 6 |
# 기준이 되는 변수를 2개 이상 묶음
ddply(data, c("year", "month"), summarise, value_avg = mean(value))
| year | month | value_avg |
|---|---|---|
|
|
|
|
| 2012 | 1 | 4 |
| 2012 | 2 | 8 |
| 2013 | 1 | 3 |
| 2013 | 2 | 5 |
# 원하는 임의의 함수를 작성해서 사용 가능
ddply(data, c("year", "month"), function(x){
value_avg = mean(x$value)
value_sd = sd(x$value)
data.frame(avg_sd = value_avg / value_sd)
})
| year | month | avg_sd |
|---|---|---|
|
|
|
|
| 2012 | 1 | 2.828427 |
| 2012 | 2 | 5.656854 |
| 2013 | 1 | 1.060660 |
| 2013 | 2 | 3.535534 |
data.table 패키지
데이터 테이블은 데이터프레임과 유사하지만 특정 칼럼별 주솟값을 갖는 인덱스를 생성하여 연산 및 검색을 빠르게 수행할 수 잇는 데이터 구조입니다. 기존 데이터프레임보다 적게는 4배에서 크게는 100배에 가까운 빠른 속도로 데이터를 탐색, 연산, 정령, 병합할 수 있게 합니다.
library(data.table)
year <- rep(c(2012:2015), each = 12000000)
month <- rep(rep(c(1:12), each = 1000000), 4)
value <- runif(48000000)
# 같은 데이터로 4800만 개의 행을 갖는 데이터프레임과 데이터 테이블을 생성
DataFrame <- data.frame(year, month, value)
DataTable <- as.data.table(DataFrame)
# 데이터 테이블의 검색 시간측정
system.time(DataTable[DataTable$year == 2012, ])
user system elapsed
0.128 0.107 0.155
- 명령문의 시작부터 종료까지 0.251초
# 데이터 테이블의 연도 칼럼에 키 값을 설정
# 칼럼이 키 값으로 설정될 경우 자동 오름차순 정렬
setkey(DataTable, year)
# 키 값으로 설정된 칼럼과 J 표현식을 사용한 검색 시간 측정
system.time(DataTable[J(2012)])
user system elapsed
0.286 0.030 0.063
- 명령문의 시작부터 종료까지 0.063초
- 키값을 활용한 데이터 테이블의 탐색 속도가 더 빠른 것을 확인할 수 있다.