분석 방법론
제1장 데이터 분석 기획의 이해
목차
1. 분석 방법론 개요
분석 방법론(Analysis Methodology)이란?
분석 방법론이란 주어진 과제를 해결하기 위해 조직이 어떠한 절차로 작업을 수행해 나갈 것인지 일련의 절차를 정의한 것 입니다. 개인 또는 소규모 조직이 분석 프로젝트를 진행할 때는 의사소통이 크게 어렵지 않기 때문에 방법론의 필요성을 느끼기 힘들 수 있습니다. 그러나 대규모 조직이 분석 프로젝트를 수핼할 때는 구성원 간의 업무 통일(Work Uniformity)을 위한 철저한 조직 관리와 더불어 성공적인 프로젝트 수행을 위한 방법론이 필수입니다.
분석 방법론의 필요성
데이터 분석이 효과적으로 기업 내에 정착하기 위해서는 이를 체계화한 절차와 방법이 정리된 데이터 분석 방법론 수립은 필수적이다. 데이터 분석 프로젝트는 개인의 역량 혹은 우연한 성공에 기인해서는 안 되고, 일정한 수준의 품질을 갖춘 산출물(Deliverables)과 프로젝트의 성공 가능성을 확보하고 제시할 수 있어야 합니다. 따라서 방법론은 절차, 방법, 도구와 기법, 템플릿과 산출물로 구성되어 있어야 합니다.
절차(Procedure): 데이터 수집(Data Collection), 데이터 전처리(Data Preprocessing), 모델링(Modeling), 평가(Evaludation), 배포(Deployment) 등 분석 과정의 각 단계를 순차적으로 정의합니다.
- 각 단계별 목표, 입력 데이터, 출력 결과, 수행 방법 등을 명시합니다.
방법(Method): 회귀 분석(Regression Analysis), 군집 분석(Clustering), 의사 결정 나무(Decision Tree), 텍스트 마이닝(Text Mining) 등 각 단계에서 사용되는 구체적인 분석 기법을 설명합니다.
- 각 기법의 장단점, 적용 조건, 결과 해석 방법 등을 제시합니다.
예시: 전문가의 자문 요구, 고객의 요구사항 파악을 위한 대면조사 등
도구와 기법(Tools & Techniques): R, Python, SQL, Hadoop, Spark 등 분석에 사용되는 소프트웨어, 프로그래밍 언어, 하드웨어 등을 명시합니다.
- 각 도구의 설치 및 사용 방법, 기법 적용 시 주의사항 등을 설명합니다.
템플릿과 산출물(Templates & Outputs): 데이터 요구사항 정의서, 데이터 전처리 보고서, 모델링 결과 보고서, 시각화 자료, 최종 보고서 등 각 단계별 산출물과 템플릿을 제공합니다.
- 산출물의 형식, 내용 작성 방법 등을 표준화합니다.
템플릿: 어떤 작업을 수행하기 위해 작성할 때 참고할 수 잇는 일종의 양식, 문서 또는 프로그램 산출물: 작업이 종료된 이후 작성되는 문서 또는 프로그램
분석 방법론의 생성 과정
일반적으로 방법론의 생성 과정을 보면 다음과 같이 개인의 암묵지(Tacit Knowledge)가 조직의 형식지(Explicit Knowledge)로 표출화(Externalisation)/형식화되고, 조직의 형식지가 체계화되어 분석 방법론이 됩니다. 체계화된 방법론은 다시 내면화(Internalisation)/내재화 과정을 거쳐 개인의 암묵지로 발전하는 순환적인 과정이 일반적인 분석 방법론의 생성 과정입니다.
2. 분석 방법론이 적용되는 업무 특성에 따른 모델
다양한 분석 프로젝트의 특성에 맞춰 적용되는 분석 방법론 모델들을 살펴보겠습니다. 각 모델은 프로젝트의 목표, 요구사항, 위험 요소 등을 고려하여 선택됩니다.
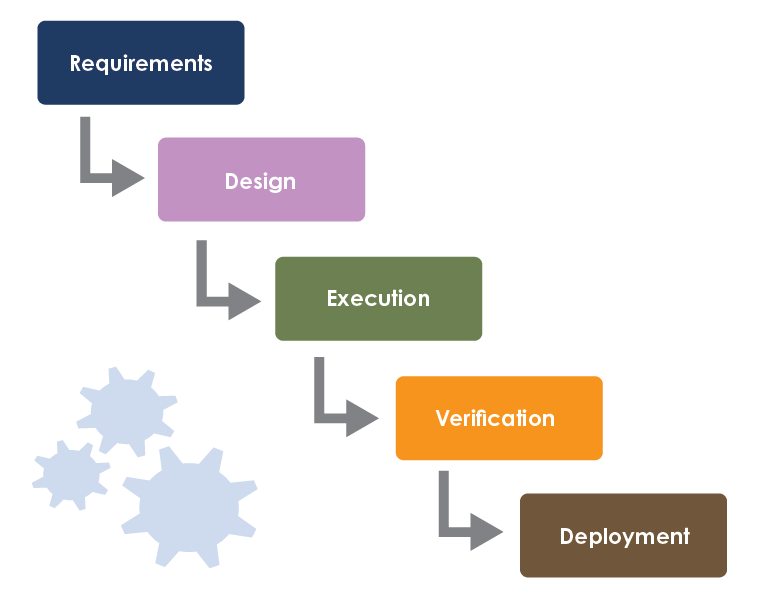
폭포수 모델(Waterfall Model)
단계를 거쳐 순차적으로 진행하는 하향식(Top-Down) 방법론으로, 현재 단계가 완료되어야 다음 단계로 진행할 수 있습니다. 하지만 문제나 개선사항이 발견될 경우 이전 단계로 돌아가 피드백 과정을 수행할 수도 있습니다.
특징:
- 각 단계가 명확하게 정의되어 있으며, 순차적으로 진행됩니다.
- 문서화가 잘 되어 있어 진행 상황을 추적하고 관리하기 용이합니다.
- 요구사항이 명확하고 변경 가능성이 낮은 프로젝트에 적합합니다.
- 초기 단계에서 모든 요구사항을 정의해야 하므로, 유연성이 부족합니다.
- 후반 단계에서는 문제가 발견될 경우 수정 비용이 높습니다.
출처: Data Science PM - What is Waterfall?
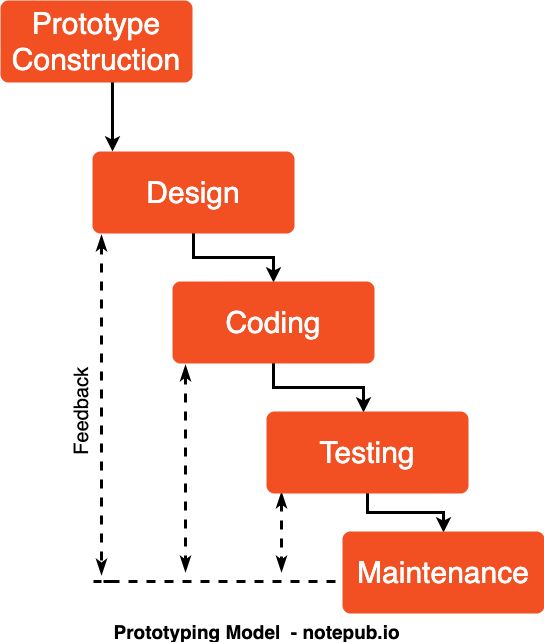
프로토타입 모델(Prototype Model)
사용자 중심의 개발 방법으로, 고객의 요구를 완전히 이해하지 못할 경우 프로토타입 모델을 적용됩니다. 일부분을 먼저 개발하고, 그 이후 사용자의 요구를 분석, 정당성 점검, 성능을 평가하는 등의 과정을 통해 개선 작업을 시행하며 점진적으로 시스템을 개발해 나가는 접근 방식입니다.
특징:
- 사용자의 피드백을 빠르게 반영하여 개발할 수 있습니다.
- 요구사항이 불분명하거나 변경 가능성이 높은 프로젝트에 적합합니다.
 출처: noteput - Prototyping Model
출처: noteput - Prototyping Model
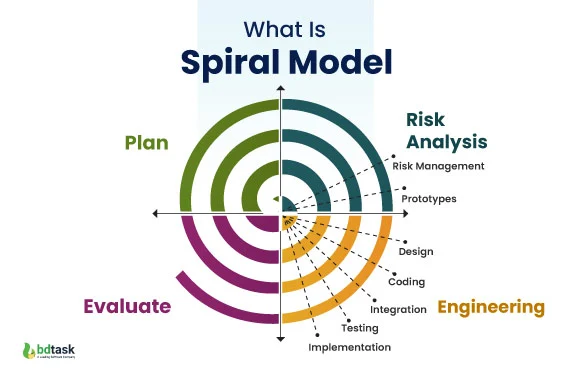
나선형 모델(Spiral Model)
반복을 통해 점증적으로 개발하는 측면에서 프로토타입 모델과 유사하지만, 사용자의 요구에 초점을 맞추기보다 위험요소를 사전에 제거한다는 것에 초점을 둡니다. 위헌 분석을 반복적으로 수행하며, 각 반복 단계에서 프로토타입을 개발하고 검토합니다.
특징:
- 위험 관리에 효과적으며, 복잡한 프로젝트에 적합합니다.
- 초기 시도 프로젝트에 적용이 용이하지만, 관리 체계를 효과적으로 갖추지 못하면 복잡도가 상승합니다.
- 반복적인 개발과 위험 분석으로 인해 개발 기간이 길어질 수 있습니다.
 출처: bdtask - Spiral Model For Software Development- A Risky-Driven Model
출처: bdtask - Spiral Model For Software Development- A Risky-Driven Model
계층적 프로세스 모델(Hierarchical Process Model)
일반적으로 분석 방법론은 계층적 프로세스 모델의 형태로 구성됩니다. 계층적 프로세스 모델은 최상의 계층인 몇 개의 단계로 구성되어 있고 하나의 단계는 여러 개의 태스크로 구성되고 하나의 태스크는 여러 개의 스텝으로 구성됩니다. 스텝은 WBS(Wrok Breakdown Structure)의 워크패키지에 해당하며, ‘입력(input) - 처리 및 도구(Process & Tool) - 출력(Output)’으로 구성된 단위 프로세스입니다.
특징:
- 프로젝트를 체계적으로 관리하고 진행할 수 있습니다.
- 각 단계, 태스크, 스텝별로 명확한 산출물을 정의하여 품질 관리를 용이하게 합니다.
- 프로젝트의 복잡도를 낮추고 효율성을 높입니다.
빅데이터 분석의 계측정 프로세스
| 단계(Phase) | 프로세스 그룹을 통해 완성된 단계별 산출물 생성, 버전 관리 등을 통한 통제 필요 |
| 태스크(Task) | 단계를 구성하는 단위 활동, 물리적 또는 논리적 단위로 품질 검토의 항목이 될 수 있음 |
| 스텝(Step) | WBS의 워크패키지에 해당하고, 입력자료, 처리 및 도구, 출력 자료로 구성된 단위 프로세스 |
 출처: Medium - Hierarchical Models for Data and Policy, and a Walk-through Tutorial!
출처: Medium - Hierarchical Models for Data and Policy, and a Walk-through Tutorial!
애자일 모델(Agile Model)
짧은 주기의 개발과 빠른 피드백을 통해 고객의 요구사항 변화에 유연하게 대응하는 방법론입니다. 스크럼(Scrum), 칸반(Kanban) 등의 다양한 방법론이 있습니다. 변화에 민감하고 빠른 개발이 필요한 프로젝트에 적합합니다.
3. 전통적인 분석 방법론 두 가지
KDD 분석 방법론
KDD(Knowledge Discovery in Databases)는 Usama M. Fayyad(American Data scientist, 1965)에 의해 고안된 분석 방법론 중 하나로, 데이터베이스에서 의미 있는 지식을 탐색하는 체계적인 프로세스입니다. 데이터 마이닝(Data Mining)을 포함하며, 기계 학습(Machine Learning), 인공지능(Artificial Intelligence), 패턴 인식(Pattern Recognition), 시각화(Visualization) 등 다양한 분야에 응용될 수 있는 구조를 가지고 있습니다.
주요 특징:
- 프로세스 중심: 데이터에서 지식을 발견하는 전체 과정을 체계적으로 관리합니다.
- 다양한 기술 통합: 데이터 마이닝, 기계 학습, 통계 등 다양한 분석 기술을 활용합니다.
- 지식 발견 목표: 데이터에서 유용한 패턴과 정보를 찾아내어 의사 결정에 활용합니다.
KDD 분석 방법론 프로세스
- 데이터 선택(Selection): 비즈니스 도메인에 대한 이해와 프로젝트 목표 설정이 필수이며, 분석에 필요한 데이터를 선택하고 타겟 데이터(target data)를 생성합니다.
- 데이터 전처리(Preprocessing): 선택된 데이터의 잡음(Noise), 이상값(Outlier), 결측치(Missing Value)를 제거하거나 의미 있는 데이터로 정제합니다. 추가로 요구되는 데이터셋이 있다면 데이터 선택 프로세스를 다시 실행합니다.
- 데이터 변환(Transformation): 분석 목적에 맞는 형태로 데이터를 변환하고 필요한 변수를 생성/선택하고 데이터의 차원을 축소하며, 학습용 데이터(training data set)와 검증용 데이터(test data set)로 분리합니다.
- 데이터 마이닝(Data Mining): 변환된 데이터에서 패턴을 발견하기 위해 학습용 데이터를 이용하여 분석 목적에 맞는 데이터 마이닝 기법을 선택하고 적절한 알고리즘을 적용합니다. 필요에 따라 전처리와 변환 프로세스도 추가합니다.
- 패턴 평가(Evaludation): 분석 목적과 일치성을 확인하고 평가합니다. 발견한 지식을 업무에 활용하기 위한 방안을 마련합니다.
- 지식 표현(Knowledge Representation): 추출된 지식을 사용자가 이해하기 쉬운 형태로 시각화하거나 보고서로 작성합니다.
데이터 마이닝(Data Mining): 대규모 데이터 집합에서 유용한 패턴이나 정보를 추출하는 기술입니다.
- 분류(Classification), 회귀(Regression), 군집화(Clustering), 연관 규칙 학습(Association Rule Learning) 등 다양한 기법이 사용됩니다.
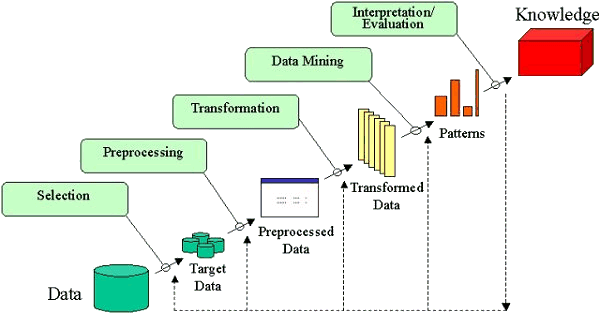 출처: Medium - KDD Process in Data Science: A Beginner’s Guide
출처: Medium - KDD Process in Data Science: A Beginner’s Guide
CRISP-DM 분석 방법론
CRISP-DM(Cross Industry Standard Process for Data Mining) 분석 방법론은 데이터 마이닝 프로젝트를 수행하기 위한 산업 표준 프로세스 모델입니다. KDD 분석 방법론과 유사하지만, 더 세분화된 단계와 유연성을 제공합니다. 1999년 유럽 연합에서 발표된 계층적 프로세스 모델로, 다른 계층적 프로세스 모델은 단계, 태스크, 스텝 3개의 레벨로 구성되어 있지만 CRISP-DM 분석 방법론은 4개의 레벨과 업무 이해, 데이터 이해, 데이터 분지, 모델링, 평가, 전개의 6단계로 구성되어 있습니다.
주요 특징:
- 산업 표준: 데이터 마이닝 프로젝트를 위한 표준 방법론으로 널리 사용됩니다.
- 유연성: 각 단계는 순차적으로 진행될 수도 있고, 필요에 따라 이전 단계로 돌아가 반복적으로 수행될 수도 있습니다.
- 실용성: 실제 비즈니스 환경에서 데이터 마이닝 프로젝트를 성공적으로 수행하기 위한 실용적인 지침을 제공합니다.
- 계층적 프로세스: 단계, 일반화 태스크, 세분화 태스크, 프로세스 실행의 4개의 레벨로 구성됩니다.
CRIP-DM 분석 방법론 프로세스
- 업무 이해(Business Understanding): 프로젝트 목표와 요구사항을 비즈니스 관점에서 이해하며, 도메인 지식을 바탕으로 데이터 마인이 문제를 정의하고 초기 프로젝트 계획을 수립합니다. 주요 태스크로는 업무 목표 파악, 상황 평가, 데이터 마이닝 목표 설정, 프로젝트 계획 수립이 있습니다.
- 데이터 이해(Data Understanding): 분석에 필요한 데이터를 수집하고 데이터의 특성을 파악합니다. 데이터의 품질 문제를 식별하고 데이터에 숨겨진 인사이트를 발견합니다. 주요 태스크로는 초기 데이터 수집, 데이터 기술 분석 및 설명, 데이터 탐색, 데이터 품질 검증이 있습니다.
- 데이터 준비(Data Preparation): 모델링에 적합한 형태로 데이터를 정제하고 변환합니다. 데이터 정제, 통합, 변환, 포맷팅 등 다양한 저처리 작업을 수행합니다. 주요 태스크로는 데이터 선택, 데이터 정제, 데이터 통합, 데이터 포맷팅이 있습니다.
- 모델링(Modeling): 적절한 모델링 기법과 알고리즘을 선택하여 모델을 구축합니다. 모델 파라미터를 최적화하고 모델의 성능을 평가합니다. 주요 태스크로는 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성 및 구축, 모델 평가가 있습니다.
- 평가(Evaluation): 구축된 모델이 프로젝트 목표에 부합하는지 평가합니다. 모델의 성능을 비즈니스 관점에서 평가하고 모델의 활용 방안을 검토합니다. 주요 태스크로는 분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가가 있습니다.
- 전개(Deployment): 구축된 모델을 실제 업무 환경에 적용합니다. 모델의 운영 및 유지보수 계획을 수립하고 프로젝트 결과를 보고합니다. 주요 태스크로는 전개 계획 수립, 모니터링 및 유지보수 계획 수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰가 있습니다.
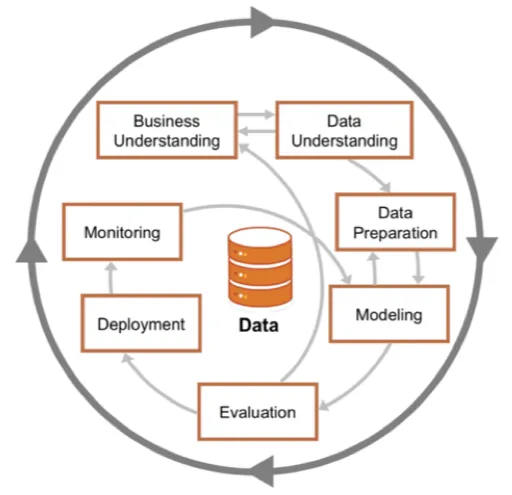 출처: Medium - Understanding CRISP-DM and its importance in Data Science projects
출처: Medium - Understanding CRISP-DM and its importance in Data Science projects