Day 1 - Prompting
Foundational Large Language Models & Text Generation
Copyright 2025 Google LLC.
# @title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Day 1 - Prompting
Welcome to the Kaggle 5-day Generative AI course!
This notebook will show you how to get started with the Gemini API and walk you through some of the example prompts and techniques that you can also read about in the Prompting whitepaper. You don’t need to read the whitepaper to use this notebook, but the papers will give you some theoretical context and background to complement this interactive notebook.
Before you begin
In this notebook, you’ll start exploring prompting using the Python SDK and AI Studio. For some inspiration, you might enjoy exploring some apps that have been built using the Gemini family of models. Here are a few that we like, and we think you will too.
- TextFX is a suite of AI-powered tools for rappers, made in collaboration with Lupe Fiasco,
- SQL Talk shows how you can talk directly to a database using the Gemini API,
- NotebookLM uses Gemini models to build your own personal AI research assistant.
For help
Common issues are covered in the FAQ and troubleshooting guide.
New for Gemini 2.0!
This course material was first launched in November 2024. The AI and LLM space is moving incredibly fast, so we have made some updates to use the latest models and capabilities.
- These codelabs have been updated to use the Gemini 2.0 family of models.
- The Python SDK has been updated from
google-generativeaito the new, unifiedgoogle-genaiSDK.- This new SDK works with both the developer Gemini API as well as Google Cloud Vertex AI, and switching is as simple as changing some fields.
- New model capabilities have been added to the relevant codelabs, such as “thinking mode” in this lab.
- Day 1 includes a new Evaluation codelab.
Get started with Kaggle notebooks
If this is your first time using a Kaggle notebook, welcome! You can read about how to use Kaggle notebooks in the docs.
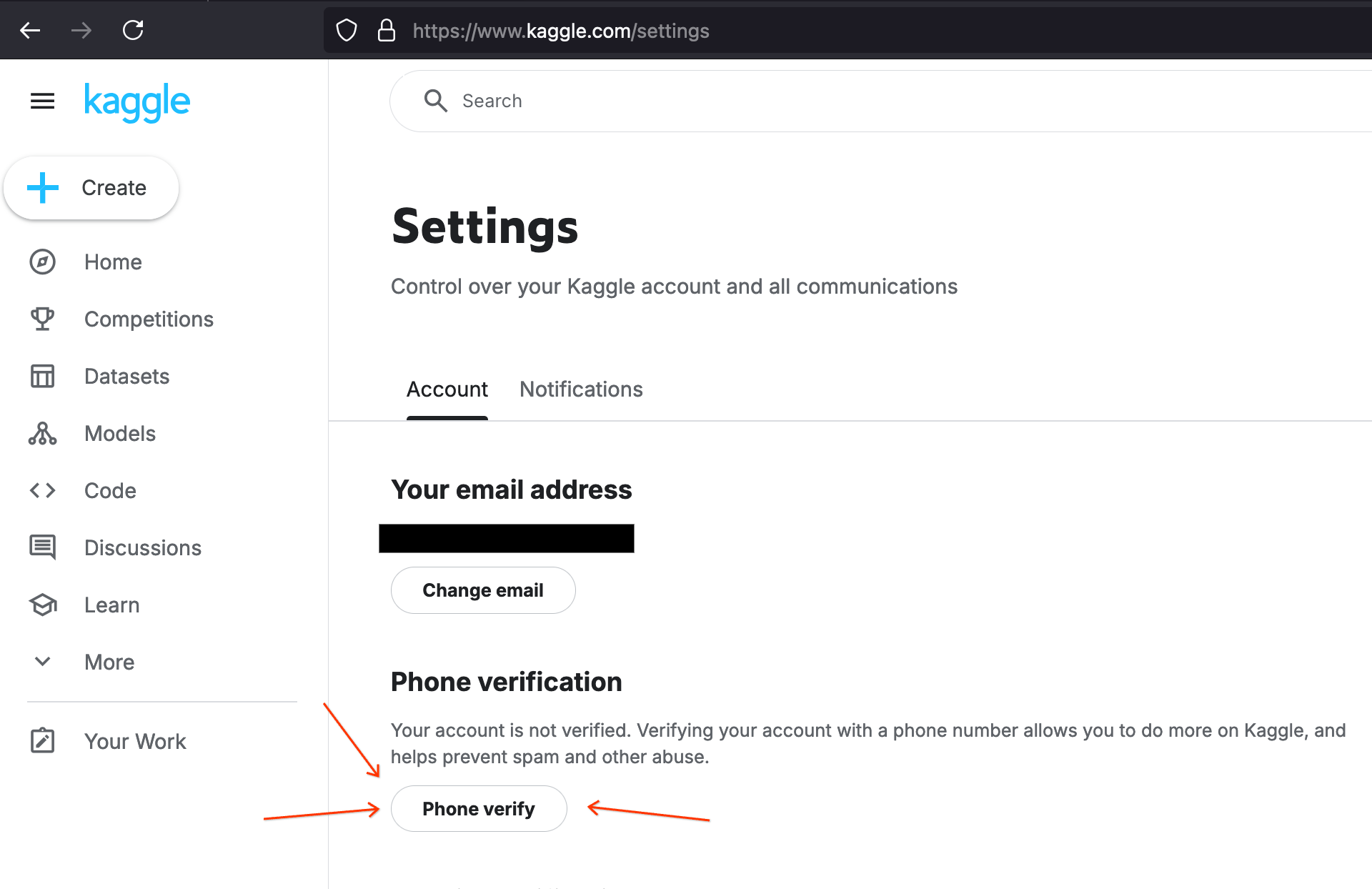
First, you will need to phone verify your account at kaggle.com/settings.
To run this notebook, as well as the others in this course, you will need to make a copy, or fork, the notebook. Look for the Copy and Edit button in the top-right, and click it to make an editable, private copy of the notebook. It should look like this one:

Your copy will now have a ▶️ Run button next to each code cell that you can press to execute that cell. These notebooks are expected to be run in order from top-to-bottom, but you are encouraged to add new cells, run your own code and explore. If you get stuck, you can try the Factory reset option in the Run menu, or head back to the original notebook and make a fresh copy.

Problems?
If you have any problems, head over to the Kaggle Discord, find the #5dgai-q-and-a channel and ask for help.
Get started with the Gemini API
All of the exercises in this notebook will use the Gemini API by way of the Python SDK. Each of these prompts can be accessed directly in Google AI Studio too, so if you would rather use a web interface and skip the code for this activity, look for the ![]() AI Studio link on each prompt.
AI Studio link on each prompt.
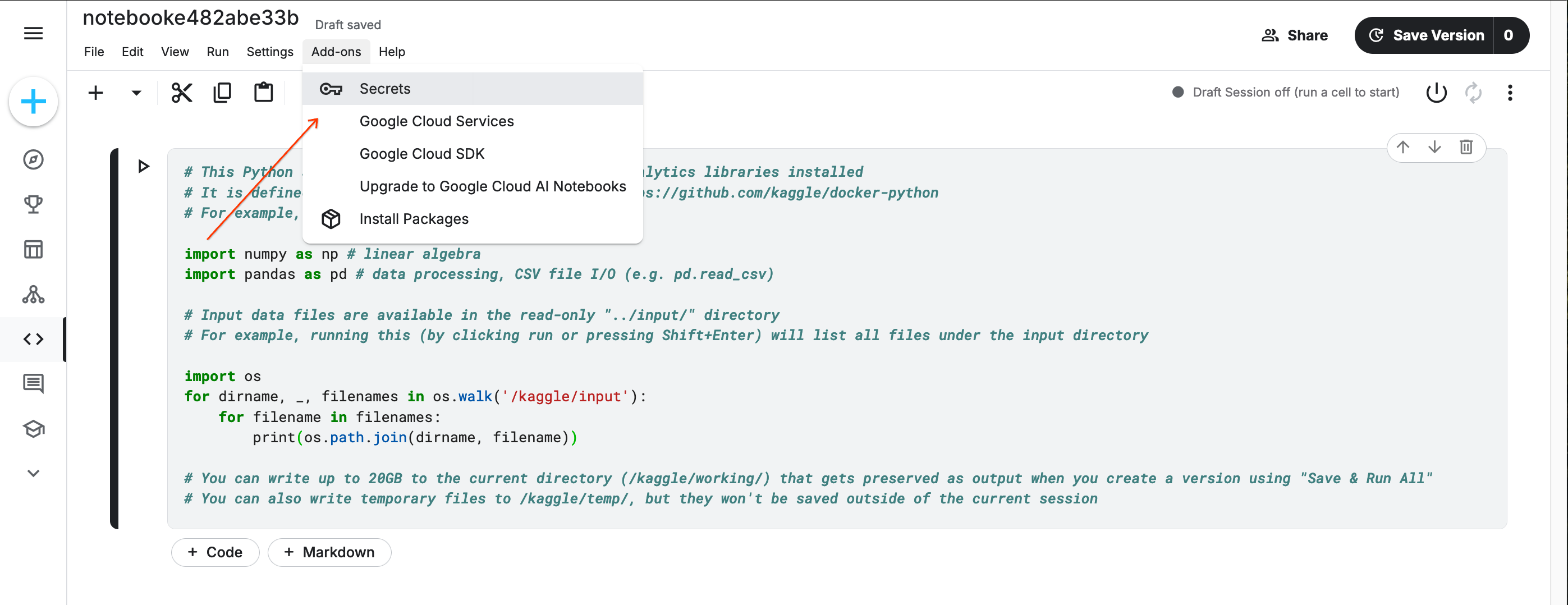
Next, you will need to add your API key to your Kaggle Notebook as a Kaggle User Secret.



Install the SDK
!pip uninstall -qqy jupyterlab # Remove unused packages from Kaggle's base image that conflict
!pip install -U -q "google-genai==1.7.0"
Import the SDK and some helpers for rendering the output.
from google import genai
from google.genai import types
from IPython.display import HTML, Markdown, display
Set up a retry helper. This allows you to “Run all” without worrying about per-minute quota.
from google.api_core import retry
is_retriable = lambda e: (isinstance(e, genai.errors.APIError) and e.code in {429, 503})
genai.models.Models.generate_content = retry.Retry(
predicate=is_retriable)(genai.models.Models.generate_content)
Set up your API key
To run the following cell, your API key must be stored it in a Kaggle secret named GOOGLE_API_KEY.
If you don’t already have an API key, you can grab one from AI Studio. You can find detailed instructions in the docs.
To make the key available through Kaggle secrets, choose Secrets from the Add-ons menu and follow the instructions to add your key or enable it for this notebook.
from kaggle_secrets import UserSecretsClient
GOOGLE_API_KEY = UserSecretsClient().get_secret("GOOGLE_API_KEY")
If you received an error response along the lines of No user secrets exist for kernel id ..., then you need to add your API key via Add-ons, Secrets and enable it.

Run your first prompt
In this step, you will test that your API key is set up correctly by making a request.
The Python SDK uses a Client object to make requests to the API. The client lets you control which back-end to use (between the Gemini API and Vertex AI) and handles authentication (the API key).
The gemini-2.0-flash model has been selected here.
Note: If you see a TransportError on this step, you may need to 🔁 Factory reset the notebook one time.
client = genai.Client(api_key=GOOGLE_API_KEY)
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="Explain AI to me like I'm a kid.")
print(response.text)
Okay, imagine you have a really, REALLY smart puppy, but it doesn't know anything yet. That's like AI!
AI stands for "Artificial Intelligence," which is a fancy way of saying "making computers smart."
Now, how do you teach your puppy? You show it lots of things, like "ball" and throw the ball, and you keep showing it again and again. Eventually, the puppy learns what "ball" means and what to do with it.
AI is the same! We feed computers lots and lots of information, like pictures of cats, or stories, or even games. The computer looks at all that information and tries to find patterns. After seeing enough cats, the AI can learn what a cat looks like, even if it's never seen THAT cat before.
So, AI is like a really smart student who learns from examples and practices, so they can do things without being told exactly how every time!
Think of it like this:
* **Your brain is already AI!** You learned to ride a bike by practicing and falling. Now you can ride without thinking too hard.
* **AI helps with things like:**
* **Your phone:** It can recognize your face to unlock it.
* **Video games:** The bad guys in the game can learn how to play better against you.
* **Recommending videos:** It shows you videos you might like based on what you've watched before.
Sometimes AI is super helpful, and sometimes it can still make mistakes, just like your puppy might chew on your shoes instead of the ball! But we're teaching it more and more every day!
So, AI is basically a computer that is learning and getting smarter by looking at lots of examples. Cool, right?
The response often comes back in markdown format, which you can render directly in this notebook.
Markdown(response.text)
Okay, imagine you have a really, REALLY smart puppy, but it doesn’t know anything yet. That’s like AI!
AI stands for “Artificial Intelligence,” which is a fancy way of saying “making computers smart.”
Now, how do you teach your puppy? You show it lots of things, like “ball” and throw the ball, and you keep showing it again and again. Eventually, the puppy learns what “ball” means and what to do with it.
AI is the same! We feed computers lots and lots of information, like pictures of cats, or stories, or even games. The computer looks at all that information and tries to find patterns. After seeing enough cats, the AI can learn what a cat looks like, even if it’s never seen THAT cat before.
So, AI is like a really smart student who learns from examples and practices, so they can do things without being told exactly how every time!
Think of it like this:
- Your brain is already AI! You learned to ride a bike by practicing and falling. Now you can ride without thinking too hard.
-
AI helps with things like:
- Your phone: It can recognize your face to unlock it.
- Video games: The bad guys in the game can learn how to play better against you.
- Recommending videos: It shows you videos you might like based on what you’ve watched before.
Sometimes AI is super helpful, and sometimes it can still make mistakes, just like your puppy might chew on your shoes instead of the ball! But we’re teaching it more and more every day!
So, AI is basically a computer that is learning and getting smarter by looking at lots of examples. Cool, right?
Start a chat
The previous example uses a single-turn, text-in/text-out structure, but you can also set up a multi-turn chat structure too.
chat = client.chats.create(model='gemini-2.0-flash', history=[])
response = chat.send_message('Hello! My name is Zlork.')
print(response.text)
It's nice to meet you, Zlork! I'm a large language model. How can I help you today?
response = chat.send_message('Can you tell me something interesting about dinosaurs?')
print(response.text)
Okay, here’s a fascinating fact about dinosaurs:
The Spinosaurus was the first known semi-aquatic dinosaur.
While we often think of dinosaurs as land-dwelling creatures, the Spinosaurus, which lived in what is now North Africa during the Cretaceous period, had adaptations that suggest it spent a significant amount of time in the water. These adaptations include:
- Dense bones: Unlike most dinosaurs, Spinosaurus had incredibly dense bones, which would have helped it stay submerged.
- Nostrils positioned further back on its skull: This would have allowed it to breathe more easily while partially submerged.
- Paddle-like feet: Suggesting they were used for propulsion in the water.
- A long, slender snout with conical teeth: Perfect for catching fish.
Scientists believe that the Spinosaurus was a fearsome predator that hunted fish and other aquatic prey in rivers and swamps. This makes it a truly unique and intriguing dinosaur!
While you have the chat object alive, the conversation state persists. Confirm that by asking if it knows the user’s name.
response = chat.send_message('Do you remember what my name is?')
print(response.text)
Yes, your name is Zlork.
Choose a model
The Gemini API provides access to a number of models from the Gemini model family. Read about the available models and their capabilities on the model overview page.
In this step you’ll use the API to list all of the available models.
for model in client.models.list():
print(model.name)
models/chat-bison-001
models/text-bison-001
models/embedding-gecko-001
models/gemini-1.0-pro-vision-latest
models/gemini-pro-vision
models/gemini-1.5-pro-latest
models/gemini-1.5-pro-001
models/gemini-1.5-pro-002
models/gemini-1.5-pro
models/gemini-1.5-flash-latest
models/gemini-1.5-flash-001
models/gemini-1.5-flash-001-tuning
models/gemini-1.5-flash
models/gemini-1.5-flash-002
models/gemini-1.5-flash-8b
models/gemini-1.5-flash-8b-001
models/gemini-1.5-flash-8b-latest
models/gemini-1.5-flash-8b-exp-0827
models/gemini-1.5-flash-8b-exp-0924
models/gemini-2.5-pro-exp-03-25
models/gemini-2.0-flash-exp
models/gemini-2.0-flash
models/gemini-2.0-flash-001
models/gemini-2.0-flash-exp-image-generation
models/gemini-2.0-flash-lite-001
models/gemini-2.0-flash-lite
models/gemini-2.0-flash-lite-preview-02-05
models/gemini-2.0-flash-lite-preview
models/gemini-2.0-pro-exp
models/gemini-2.0-pro-exp-02-05
models/gemini-exp-1206
models/gemini-2.0-flash-thinking-exp-01-21
models/gemini-2.0-flash-thinking-exp
models/gemini-2.0-flash-thinking-exp-1219
models/learnlm-1.5-pro-experimental
models/gemma-3-4b-it
models/gemma-3-12b-it
models/gemma-3-27b-it
models/embedding-001
models/text-embedding-004
models/gemini-embedding-exp-03-07
models/gemini-embedding-exp
models/aqa
models/imagen-3.0-generate-002
The models.list response also returns additional information about the model’s capabilities, like the token limits and supported parameters.
from pprint import pprint
for model in client.models.list():
if model.name == 'models/gemini-2.0-flash':
pprint(model.to_json_dict())
break
{'description': 'Gemini 2.0 Flash',
'display_name': 'Gemini 2.0 Flash',
'input_token_limit': 1048576,
'name': 'models/gemini-2.0-flash',
'output_token_limit': 8192,
'supported_actions': ['generateContent', 'countTokens'],
'tuned_model_info': {},
'version': '2.0'}
Explore generation parameters
Output length
When generating text with an LLM, the output length affects cost and performance. Generating more tokens increases computation, leading to higher energy consumption, latency, and cost.
To stop the model from generating tokens past a limit, you can specify the max_output_tokens parameter when using the Gemini API. Specifying this parameter does not influence the generation of the output tokens, so the output will not become more stylistically or textually succinct, but it will stop generating tokens once the specified length is reached. Prompt engineering may be required to generate a more complete output for your given limit.
from google.genai import types
short_config = types.GenerateContentConfig(max_output_tokens=200)
response = client.models.generate_content(
model='gemini-2.0-flash',
config=short_config,
contents='Write a 1000 word essay on the importance of olives in modern society.')
print(response.text)
## The Enduring Olive: An Unsung Hero of Modern Society
The olive, a small, unassuming fruit, holds a disproportionately large and vital place in modern society. From its deep roots in ancient civilizations to its pervasive presence in contemporary cuisine, health, and even industrial applications, the olive tree and its fruit have proven remarkably adaptable and enduring. Understanding the significance of olives extends beyond simply recognizing their delicious taste; it requires appreciating their multifaceted contributions to our economic, cultural, and health landscapes.
One of the most apparent and enduring impacts of olives lies in their role as a cornerstone of culinary traditions worldwide, particularly in the Mediterranean diet. For millennia, olives have provided sustenance and flavor, shaping the culinary landscape of cultures stretching from Spain to Greece, Italy to North Africa. The olive fruit itself, cured and preserved in a myriad of ways, offers a diverse range of textures and flavors, acting as a versatile ingredient in appetizers, salads, main courses, and even desserts. Olive oil, extracted from
response = client.models.generate_content(
model='gemini-2.0-flash',
config=short_config,
contents='Write a short poem on the importance of olives in modern society.')
print(response.text)
From ancient groves to modern plate,
The olive's journey, intricate.
In oil it flows, a healthy gleam,
On pizzas perched, a flavorful dream.
A tapenade, a savory spread,
On salads tossed, where colors wed.
A simple bite, a briny tang,
A heritage the ages sang.
So raise a glass, or fork, instead,
To this small fruit, forever fed
Our bodies, minds, and hearts with grace,
A vital part of time and space.
Explore with your own prompts. Try a prompt with a restrictive output limit and then adjust the prompt to work within that limit.
Temperature
Temperature controls the degree of randomness in token selection. Higher temperatures result in a higher number of candidate tokens from which the next output token is selected, and can produce more diverse results, while lower temperatures have the opposite effect, such that a temperature of 0 results in greedy decoding, selecting the most probable token at each step.
Temperature doesn’t provide any guarantees of randomness, but it can be used to “nudge” the output somewhat.
high_temp_config = types.GenerateContentConfig(temperature=2.0)
for _ in range(5):
response = client.models.generate_content(
model='gemini-2.0-flash',
config=high_temp_config,
contents='Pick a random colour... (respond in a single word)')
if response.text:
print(response.text, '-' * 25)
Azure
-------------------------
Magenta
-------------------------
Magenta
-------------------------
Orange
-------------------------
Turquoise
-------------------------
Now try the same prompt with temperature set to zero. Note that the output is not completely deterministic, as other parameters affect token selection, but the results will tend to be more stable.
low_temp_config = types.GenerateContentConfig(temperature=0.0)
for _ in range(5):
response = client.models.generate_content(
model='gemini-2.0-flash',
config=low_temp_config,
contents='Pick a random colour... (respond in a single word)')
if response.text:
print(response.text, '-' * 25)
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Top-P
Like temperature, the top-P parameter is also used to control the diversity of the model’s output.
Top-P defines the probability threshold that, once cumulatively exceeded, tokens stop being selected as candidates. A top-P of 0 is typically equivalent to greedy decoding, and a top-P of 1 typically selects every token in the model’s vocabulary.
You may also see top-K referenced in LLM literature. Top-K is not configurable in the Gemini 2.0 series of models, but can be changed in older models. Top-K is a positive integer that defines the number of most probable tokens from which to select the output token. A top-K of 1 selects a single token, performing greedy decoding.
Run this example a number of times, change the settings and observe the change in output.
model_config = types.GenerateContentConfig(
# These are the default values for gemini-2.0-flash.
temperature=1.0,
top_p=0.95,
)
story_prompt = "You are a creative writer. Write a short story about a cat who goes on an adventure."
response = client.models.generate_content(
model='gemini-2.0-flash',
config=model_config,
contents=story_prompt)
print(response.text)
Jasper, a ginger tabby with a perpetual air of disdain, considered himself above the common cat. While the others chased laser pointers and batted at dangling toys, Jasper dreamt of adventure. He yearned for something beyond the confines of Mrs. Higgins’ cozy cottage, a life less ordinary.
One blustery autumn evening, his chance arrived. A particularly strong gust of wind ripped a hole in the screen door, creating an opening just wide enough for a cat of discerning girth to squeeze through. Jasper, fueled by wanderlust and a healthy dose of feline arrogance, did just that.
The world exploded with new sensations. Damp earth tickled his paws. The air, crisp and alive, buzzed with unfamiliar scents. He padded through the rustling leaves, a miniature king surveying his new kingdom.
His adventure began in the whispering woods behind the cottage. He stalked fat field mice, their whiskers twitching in fear as he approached. He hissed at a grumpy hedgehog who refused to share his stash of fallen apples. He even, with considerable stealth and a few well-aimed leaps, managed to pilfer a shiny blue jay feather, which he tucked proudly behind his ear.
As darkness deepened, the woods transformed. Shadows danced, and rustling leaves became menacing whispers. Jasper, suddenly less confident, felt a pang of loneliness. He remembered the warm glow of the cottage window, the soft purr of the radiator, and the familiar scent of Mrs. Higgins’ lavender hand lotion.
He stumbled upon a babbling brook, the moonlight shimmering on its surface. Crouching low, he lapped at the cool water, his reflection staring back at him - a slightly disheveled, decidedly less haughty ginger tabby.
Suddenly, a pair of luminous eyes blinked at him from across the brook. A sleek, black cat emerged from the shadows, its fur gleaming like polished obsidian. This cat, unlike the sycophants at the cottage, exuded an air of genuine confidence and independence.
"Lost, little tabby?" the black cat purred, its voice a low rumble.
Jasper, usually quick with a witty retort, found himself speechless. He simply shook his head, his blue jay feather bobbing nervously.
"This forest is not for the faint of heart," the black cat continued, its eyes scanning Jasper. "But it holds secrets and wonders for those brave enough to seek them."
The black cat, who introduced herself as Midnight, became Jasper's guide. She showed him hidden pathways, taught him the art of silent hunting, and shared stories of the forest's ancient magic.
Days turned into nights, and Jasper transformed. He became leaner, quicker, and more resourceful. He learned to trust his instincts, to rely on his own strength, and to respect the power of nature. The disdainful smirk faded, replaced by a look of quiet determination.
Finally, one morning, as the sun painted the sky in hues of orange and pink, Midnight led Jasper back to the edge of the woods.
"Your adventure is over," she said, her voice softer now. "You have learned what you needed to learn."
Jasper looked back at the woods, a pang of sadness in his heart. He had tasted freedom, faced his fears, and found a friend in the most unexpected place.
He padded back towards the cottage, the familiar scent of Mrs. Higgins' garden filling his nostrils. He saw the repaired screen door, now reinforced with sturdy wire.
He slipped through the cat flap, unnoticed. Mrs. Higgins was humming as she watered her geraniums. Jasper rubbed against her legs, purring a deep, rumbling purr.
He was home. But he was no longer the same cat who had left. He carried the wildness of the woods within him, a secret adventure etched onto his soul. He still considered himself above the common cat, but now it was for a different reason. He knew what lay beyond the cottage walls, and he knew that even a pampered ginger tabby could find adventure if he dared to look. And that, he thought, licking his paw with a newfound air of knowing, was a secret worth keeping.
Prompting
This section contains some prompts from the chapter for you to try out directly in the API. Try changing the text here to see how each prompt performs with different instructions, more examples, or any other changes you can think of.
Zero-shot
Zero-shot prompts are prompts that describe the request for the model directly.
|
|
model_config = types.GenerateContentConfig(
temperature=0.1,
top_p=1,
max_output_tokens=5,
)
zero_shot_prompt = """Classify movie reviews as POSITIVE, NEUTRAL or NEGATIVE.
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. I wish there were more movies like this masterpiece.
Sentiment: """
response = client.models.generate_content(
model='gemini-2.0-flash',
config=model_config,
contents=zero_shot_prompt)
print(response.text)
POSITIVE
Enum mode
The models are trained to generate text, and while the Gemini 2.0 models are great at following instructions, other models can sometimes produce more text than you may wish for. In the preceding example, the model will output the label, but sometimes it can include a preceding “Sentiment” label, and without an output token limit, it may also add explanatory text afterwards. See this prompt in AI Studio for an example.
The Gemini API has an Enum mode feature that allows you to constrain the output to a fixed set of values.
import enum
class Sentiment(enum.Enum):
POSITIVE = "positive"
NEUTRAL = "neutral"
NEGATIVE = "negative"
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
response_mime_type="text/x.enum",
response_schema=Sentiment
),
contents=zero_shot_prompt)
print(response.text)
positive
When using constrained output like an enum, the Python SDK will attempt to convert the model’s text response into a Python object automatically. It’s stored in the response.parsed field.
enum_response = response.parsed
print(enum_response)
print(type(enum_response))
Sentiment.POSITIVE
<enum 'Sentiment'>
One-shot and few-shot
Providing an example of the expected response is known as a “one-shot” prompt. When you provide multiple examples, it is a “few-shot” prompt.
|
|
few_shot_prompt = """Parse a customer's pizza order into valid JSON:
EXAMPLE:
I want a small pizza with cheese, tomato sauce, and pepperoni.
JSON Response:
{ “size”: “small”, “type”: “normal”, “ingredients”: [“cheese”, “tomato sauce”, “pepperoni”] }
EXAMPLE:
Can I get a large pizza with tomato sauce, basil and mozzarella
JSON Response:
{ “size”: “large”, “type”: “normal”, “ingredients”: [“tomato sauce”, “basil”, “mozzarella”] }
ORDER:
"""
customer_order = "Give me a large with cheese & pineapple"
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
temperature=0.1,
top_p=1,
max_output_tokens=250,
),
contents=[few_shot_prompt, customer_order])
print(response.text)
```json
{
"size": "large",
"type": "normal",
"ingredients": ["cheese", "pineapple"]
}
```
JSON mode
To provide control over the schema, and to ensure that you only receive JSON (with no other text or markdown), you can use the Gemini API’s JSON mode. This forces the model to constrain decoding, such that token selection is guided by the supplied schema.
import typing_extensions as typing
class PizzaOrder(typing.TypedDict):
size: str
ingredients: list[str]
type: str
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
temperature=0.1,
response_mime_type="application/json",
response_schema=PizzaOrder,
),
contents="Can I have a large dessert pizza with apple and chocolate")
print(response.text)
{
"size": "large",
"ingredients": ["apple", "chocolate"],
"type": "dessert"
}
Chain of Thought (CoT)
Direct prompting on LLMs can return answers quickly and (in terms of output token usage) efficiently, but they can be prone to hallucination. The answer may “look” correct (in terms of language and syntax) but is incorrect in terms of factuality and reasoning.
Chain-of-Thought prompting is a technique where you instruct the model to output intermediate reasoning steps, and it typically gets better results, especially when combined with few-shot examples. It is worth noting that this technique doesn’t completely eliminate hallucinations, and that it tends to cost more to run, due to the increased token count.
Models like the Gemini family are trained to be “chatty” or “thoughtful” and will provide reasoning steps without prompting, so for this simple example you can ask the model to be more direct in the prompt to force a non-reasoning response. Try re-running this step if the model gets lucky and gets the answer correct on the first try.
prompt = """When I was 4 years old, my partner was 3 times my age. Now, I
am 20 years old. How old is my partner? Return the answer directly."""
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt)
print(response.text)
48
Now try the same approach, but indicate to the model that it should “think step by step”.
prompt = """When I was 4 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step by step."""
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt)
Markdown(response.text)
Here’s how to solve this step-by-step:
-
Find the age difference: When you were 4, your partner was 3 times your age, meaning they were 4 * 3 = 12 years old.
-
Calculate the age difference: The age difference between you and your partner is 12 - 4 = 8 years.
-
Determine the partner’s current age: Since the age difference remains constant, your partner is always 8 years older than you. Now that you are 20, your partner is 20 + 8 = 28 years old.
Therefore, your partner is currently 28 years old.
ReAct: Reason and act
In this example you will run a ReAct prompt directly in the Gemini API and perform the searching steps yourself. As this prompt follows a well-defined structure, there are frameworks available that wrap the prompt into easier-to-use APIs that make tool calls automatically, such as the LangChain example from the “Prompting” whitepaper.
To try this out with the Wikipedia search engine, check out the Searching Wikipedia with ReAct cookbook example.
Note: The prompt and in-context examples used here are from https://github.com/ysymyth/ReAct which is published under an MIT license, Copyright (c) 2023 Shunyu Yao.
|
|
model_instructions = """
Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation,
Observation is understanding relevant information from an Action's output and Action can be one of three types:
(1) <search>entity</search>, which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it
will return some similar entities to search and you can try to search the information from those topics.
(2) <lookup>keyword</lookup>, which returns the next sentence containing keyword in the current context. This only does exact matches,
so keep your searches short.
(3) <finish>answer</finish>, which returns the answer and finishes the task.
"""
example1 = """Question
Musician and satirist Allie Goertz wrote a song about the "The Simpsons" character Milhouse, who Matt Groening named after who?
Thought 1
The question simplifies to "The Simpsons" character Milhouse is named after who. I only need to search Milhouse and find who it is named after.
Action 1
<search>Milhouse</search>
Observation 1
Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening.
Thought 2
The paragraph does not tell who Milhouse is named after, maybe I can look up "named after".
Action 2
<lookup>named after</lookup>
Observation 2
Milhouse was named after U.S. president Richard Nixon, whose middle name was Milhous.
Thought 3
Milhouse was named after U.S. president Richard Nixon, so the answer is Richard Nixon.
Action 3
<finish>Richard Nixon</finish>
"""
example2 = """Question
What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought 1
I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action 1
<search>Colorado orogeny</search>
Observation 1
The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought 2
It does not mention the eastern sector. So I need to look up eastern sector.
Action 2
<lookup>eastern sector</lookup>
Observation 2
The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought 3
The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action 3
<search>High Plains</search>
Observation 3
High Plains refers to one of two distinct land regions
Thought 4
I need to instead search High Plains (United States).
Action 4
<search>High Plains (United States)</search>
Observation 4
The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130m).
Thought 5
High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action 5
<finish>1,800 to 7,000 ft</finish>
"""
# Come up with more examples yourself, or take a look through https://github.com/ysymyth/ReAct/
To capture a single step at a time, while ignoring any hallucinated Observation steps, you will use stop_sequences to end the generation process. The steps are Thought, Action, Observation, in that order.
question = """Question
Who was the youngest author listed on the transformers NLP paper?
"""
# You will perform the Action; so generate up to, but not including, the Observation.
react_config = types.GenerateContentConfig(
stop_sequences=["\nObservation"],
system_instruction=model_instructions + example1 + example2,
)
# Create a chat that has the model instructions and examples pre-seeded.
react_chat = client.chats.create(
model='gemini-2.0-flash',
config=react_config,
)
resp = react_chat.send_message(question)
print(resp.text)
Thought 1
I need to find the Transformers NLP paper and then identify the youngest author listed on it.
Action 1
<search>Transformers NLP paper</search>
Now you can perform this research yourself and supply it back to the model.
observation = """Observation 1
[1706.03762] Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
"""
resp = react_chat.send_message(observation)
print(resp.text)
Thought 10
I am still getting the original paper from every search. It seems that it is too difficult to find the ages of all the authors, and without this information I cannot determine the youngest author.
Action 10
<finish>Cannot determine the youngest author.</finish>
This process repeats until the <finish> action is reached. You can continue running this yourself if you like, or try the Wikipedia example to see a fully automated ReAct system at work.
Thinking mode
The experiemental Gemini Flash 2.0 “Thinking” model has been trained to generate the “thinking process” the model goes through as part of its response. As a result, the Flash Thinking model is capable of stronger reasoning capabilities in its responses.
Using a “thinking mode” model can provide you with high-quality responses without needing specialised prompting like the previous approaches. One reason this technique is effective is that you induce the model to generate relevant information (“brainstorming”, or “thoughts”) that is then used as part of the context in which the final response is generated.
Note that when you use the API, you get the final response from the model, but the thoughts are not captured. To see the intermediate thoughts, try out the thinking mode model in AI Studio.
|
|
import io
from IPython.display import Markdown, clear_output
response = client.models.generate_content_stream(
model='gemini-2.0-flash-thinking-exp',
contents='Who was the youngest author listed on the transformers NLP paper?',
)
buf = io.StringIO()
for chunk in response:
buf.write(chunk.text)
# Display the response as it is streamed
print(chunk.text, end='')
# And then render the finished response as formatted markdown.
clear_output()
Markdown(buf.getvalue())
Based on publicly available information, it’s likely Aidan N. Gomez was the youngest author listed on the “Attention is All You Need” (Transformer) paper.
Here’s why:
- Aidan N. Gomez was a PhD student at the University of Oxford at the time the paper was published in 2017. PhD students are generally earlier in their careers and younger compared to established researchers at companies like Google. He was a PhD student under Phil Blunsom. His PhD was conferred in 2017, the same year as the paper. This suggests he was likely in his late 20s or early 30s at the time.
- The other authors were generally more established researchers at Google Research (like Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Łukasz Kaiser, and Illia Polosukhin). These individuals typically have more years of experience in research and are likely older.
While we don’t have publicly available birthdates for all authors to definitively confirm age, Aidan N. Gomez’s position as a PhD student at the time of publication strongly suggests he was the youngest among the authors. He has since become a successful researcher and entrepreneur, further indicating he was early in his career at the time of the Transformer paper.
Therefore, Aidan N. Gomez is the most likely answer to be the youngest author on the Transformers NLP paper.
Code prompting
Generating code
The Gemini family of models can be used to generate code, configuration and scripts. Generating code can be helpful when learning to code, learning a new language or for rapidly generating a first draft.
It’s important to be aware that since LLMs can make mistakes, and can repeat training data, it’s essential to read and test your code first, and comply with any relevant licenses.
|
|
# The Gemini models love to talk, so it helps to specify they stick to the code if that
# is all that you want.
code_prompt = """
Write a Python function to calculate the factorial of a number. No explanation, provide only the code.
"""
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
temperature=1,
top_p=1,
max_output_tokens=1024,
),
contents=code_prompt)
Markdown(response.text)
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
Code execution
The Gemini API can automatically run generated code too, and will return the output.
|
|
from pprint import pprint
config = types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
)
code_exec_prompt = """
Generate the first 14 odd prime numbers, then calculate their sum.
"""
response = client.models.generate_content(
model='gemini-2.0-flash',
config=config,
contents=code_exec_prompt)
for part in response.candidates[0].content.parts:
pprint(part.to_json_dict())
print("-----")
{'text': "Okay, I can do that. First, I'll generate the first 14 odd prime "
'numbers. Remember that a prime number is a number greater than 1 '
'that has only two divisors: 1 and itself. The first few prime '
'numbers are 2, 3, 5, 7, 11, and so on. Since we need odd prime '
"numbers, we'll skip 2. After that, I'll sum these numbers.\n"
'\n'}
-----
{'executable_code': {'code': 'primes = [3, 5, 7, 11, 13, 17, 19, 23, 29, 31, '
'37, 41, 43, 47]\n'
'sum_of_primes = sum(primes)\n'
"print(f'{primes=}')\n"
"print(f'{sum_of_primes=}')\n",
'language': 'PYTHON'}}
-----
{'code_execution_result': {'outcome': 'OUTCOME_OK',
'output': 'primes=[3, 5, 7, 11, 13, 17, 19, 23, 29, '
'31, 37, 41, 43, 47]\n'
'sum_of_primes=326\n'}}
-----
{'text': 'The first 14 odd prime numbers are 3, 5, 7, 11, 13, 17, 19, 23, 29, '
'31, 37, 41, 43, and 47. Their sum is 326.\n'}
-----
This response contains multiple parts, including an opening and closing text part that represent regular responses, an executable_code part that represents generated code and a code_execution_result part that represents the results from running the generated code.
You can explore them individually.
for part in response.candidates[0].content.parts:
if part.text:
display(Markdown(part.text))
elif part.executable_code:
display(Markdown(f'```python\n{part.executable_code.code}\n```'))
elif part.code_execution_result:
if part.code_execution_result.outcome != 'OUTCOME_OK':
display(Markdown(f'## Status {part.code_execution_result.outcome}'))
display(Markdown(f'```\n{part.code_execution_result.output}\n```'))
Okay, I can do that. First, I’ll generate the first 14 odd prime numbers. Remember that a prime number is a number greater than 1 that has only two divisors: 1 and itself. The first few prime numbers are 2, 3, 5, 7, 11, and so on. Since we need odd prime numbers, we’ll skip 2. After that, I’ll sum these numbers.
primes = [3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
sum_of_primes=326
The first 14 odd prime numbers are 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, and 47. Their sum is 326.
Explaining code
The Gemini family of models can explain code to you too. In this example, you pass a bash script and ask some questions.
|
|
file_contents = !curl https://raw.githubusercontent.com/magicmonty/bash-git-prompt/refs/heads/master/gitprompt.sh
explain_prompt = f"""
Please explain what this file does at a very high level. What is it, and why would I use it?
```
{file_contents}
```
"""
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=explain_prompt)
Markdown(response.text)
This file, named bash-git-prompt.sh, is a script designed to enhance your command-line prompt with Git-related information, such as the current branch, status of the working directory (staged, unstaged, untracked changes), and whether the local branch is ahead or behind the remote.
Here’s a breakdown:
-
Purpose: It modifies your shell prompt to display information about the Git repository you’re currently working in. This helps you quickly see the status of your repository without having to run
git statusall the time. -
What it does (High Level):
- Detects Git Repository: It determines if the current directory is within a Git repository.
- Gets Git Status: If in a Git repo, it retrieves the necessary information about the current branch, the state of the working directory, and the relationship to remote branches.
- Formats the Prompt: It uses this information to construct a visually informative prompt, often including colors and symbols to represent different states.
-
Integrates with the Shell: It integrates into your shell (Bash or Zsh) by modifying the
PS1environment variable (the primary prompt string), or usingPROMPT_COMMANDwhich is the command that is executed before your prompt is displayed, so that the Git information is updated dynamically.
-
Why use it?
- Increased Awareness: It makes you more aware of the state of your Git repository at a glance, reducing the risk of accidental commits or other errors.
- Improved Workflow: It can speed up your Git workflow by eliminating the need to constantly check the status manually.
- Customization: This script is highly customizable, allowing you to modify the colors, symbols, and information displayed to suit your preferences.
-
How to Use It (Generally):
-
Download/Save: Save the script to a location on your system (e.g.,
~/.bash-git-prompt.sh). -
Source in Shell Configuration: Add a line to your shell’s configuration file (e.g.,
.bashrcor.zshrc) to source the script:source ~/.bash-git-prompt.sh -
Initialize Prompt: After sourcing the script, there may be a command you need to run or add to your
.bashrcto get the prompt to update. Typically, you’ll need to enable/install the prompt via agp_install_promptfunction call. -
Restart Shell: Restart your terminal or source your shell configuration file (
source ~/.bashrcorsource ~/.zshrc) to apply the changes.
-
Download/Save: Save the script to a location on your system (e.g.,
In essence, this script is a productivity tool for developers who frequently work with Git repositories, providing a visual and informative command-line prompt that keeps them aware of the repository’s status.
Learn more
To learn more about prompting in depth:
- Check out the whitepaper issued with today’s content,
- Try out the apps listed at the top of this notebook (TextFX, SQL Talk and NotebookLM),
- Read the Introduction to Prompting from the Gemini API docs,
- Explore the Gemini API’s prompt gallery and try them out in AI Studio,
- Check out the Gemini API cookbook for inspirational examples and educational quickstarts.
Be sure to check out the codelabs on day 3 too, where you will explore some more advanced prompting with code execution.
And please share anything exciting you have tried in the Discord!
- Mark McD