데이터와 정보
과목 Ⅰ 제1장 데이터의 이해
목차
1. 데이터의 정의
데이터란 무엇인가?
데이터(Data)는 라틴어 ‘dare(주다)’에서 유래된 ‘Datum(주어진 것, 자료)’에서 비롯된 용어로, 본래는 연구나 조사, 분석 등의 기반이 되는 정보를 뜻한다. 최초의 문헌 기록은 1646년 영국에서 발견되며, 당시에는 개념적이고 추상적인 의미로 사용되었다. 이후 20세기 중반 컴퓨터의 등장과 함께 데이터는 기술적이고 사실적인 의미로 확장되었으며, 현재는 디지털 환경에서 핵심 자원으로 간주된다.
데이터의 특성
데이터는 본질적으로 두 가지 특성을 지닌다. 첫째, 있는 그대로의 사실이나 상태를 기록한 존재적 특성이다. 이는 특정 시점에 관측되거나 측정된 결과를 의미하며, 예를 들어 “고객 A는 2025년 3월 1일 제품 B를 구매했다”는 사실이 이에 해당한다. 둘째, 특정 목적이나 의사결정을 위한 해석이나 판단의 근거로 사용되는 당위적 특성이다. 예를 들어, “제품 B의 월간 판매량이 꾸준히 증가하고 있으므로 마케팅을 강화할 필요가 있다”는 해석은 존재적 데이터를 바탕으로 한 당위적 판단이다.
| 구분 | 존재적 특성 (Ontological) | 당위적 특성 (Normative) |
|---|---|---|
| 정의 | 관찰, 측정 등을 통해 얻은 있는 그대로의 사실 | 해석, 추론, 의사결정 등 정보로서 활용 가능한 판단의 근거 |
| 목적 | 데이터 자체의 기록 및 저장 | 데이터 기반의 분석·예측·판단을 위한 기반 |
| 특징 | 객관적이며 변화하지 않음 | 분석자의 관점에 따라 해석이 달라질 수 있음 |
| 예시 | 고객 A는 3월 1일에 제품 B를 구매함 | 제품 B의 월간 판매량이 증가하므로 마케팅 예산을 확대할 필요가 있음 |
| 활용 관점 | 데이터 수집, 저장, 정제 등 기초단계에 활용 | 데이터 분석, 시각화, 인사이트 도출 등 고차원적 분석 단계에 활용 |
데이터와 정보의 차이
데이터는 가공되지 않은 사실의 조각이며, 정보는 이러한 데이터를 맥락과 목적에 따라 해석한 결과물입니다. 예를 들어, “홍길동의 키는 175cm다”는 데이터이지만, “홍길동은 평균보다 키가 크다”는 정보입니다.
정리하자면, 데이터는 입력, 정보는 출력에 가깝고, 정보는 데이터에 ‘의미’를 부여했을 때 탄생합니다.
데이터의 유형
데이터는 정보의 성격과 데이터 구조의 형식에 따라 분류됩니다. 이는 데이터의 분석 목적, 처리 방식, 저장 형태에 따라 서로 다른 접근법이 요구되기 때문에 명확한 구분이 필요합니다.
정보의 성격에 따른 분류
정성적 데이터(Qualitative Data): 수치가 아닌 속성, 특성, 범주 등의 형태로 표현되는 데이터입니다. 대개 언어적 표현을 기반으로 하며, 범주형(Categorical) 데이터로 분류됩니다. 주로 설문, 인터뷰, 관찰 등의 방식으로 수집되며, 분류나 그룹화에 적합합니다.
- 예시: 성별, 혈액형, 국적, 브랜드 선호도 등
정량적 데이터(Quantitative Data): 수치로 표현되며, 측정 가능하고 수학적 연산이 가능한 데이터를 의미합니다. 이는 다시 이산형(Discrete)과 연속형(Continuous)으로 나뉘며, 정량적 데이터는 평균, 표준편차, 합계 등의 통계 분석에 활용된다.
-
이산형(Discrete): 정수 단위로 측정 (예: 학생 수, 판매 건수)
-
연속형(Continuous): 연속적 수치로 측정 가능 (예: 키, 체중, 온도)
-
예시: 나이, 소득, 키, 시험 점수 등
데이터 구조 형식에 따른 분류
정형데이터(Structured Data): 행과 열로 구성된 고정된 형식을 가진 데이터로, 관계형 데이터베이스(RDBMS)나 스프레드시트 등에서 주로 사용됩니다. 사전에 정의된 스키마에 따라 저장되기 때문에 검색, 정렬, 통계 등의 처리가 용이합니다.
- 예시: Excel 테이블, 고객 DB, 재무 정보
비정형데이터(Unstructured Data): 고정된 형식이나 구조 없이 저장되는 데이터로, 텍스트, 이미지, 음성, 영상 등 다양한 형태를 포함합니다. 정형데이터와 달리 명확한 스키마가 없어 처리 및 분석을 위해 전처리나 특수한 기술이 요구됩니다.
- 예시: SNS 댓글, 이메일 내용, 사진, 동영상
반정형데이터(Semi-structured Data): 구조화된 태그나 구분자를 포함해 데이터 간의 관계나 의미를 표현할 수 있지만, 정형데이터처럼 완전한 스키마를 따르지는 않는 데이터입니다. 일정한 규칙은 존재하지만 유연성이 높아 다양한 형식으로 표현될 수 있습니다.
- 예시: JSON, XML, HTML, 웹 로그 파일
| 기준 | 유형 | 설명 | 예시 |
|---|---|---|---|
| 정보의 성격 | 정성적 데이터 | 수치가 아닌 속성과 범주로 표현 | 성별, 혈액형, 지역명 |
| 정보의 성격 | 정량적 데이터 | 수치로 표현되고 수학적 연산 가능 | 나이, 수입, 키 |
| 데이터 구조 형식 | 정형 데이터 | 행/열 기반의 고정된 구조 | 엑셀, 관계형 DB (RDB) |
| 데이터 구조 형식 | 반정형 데이터 | 태그 포함, 유연한 구조 | JSON, XML, 로그 파일 |
| 데이터 구조 형식 | 비정형 데이터 | 구조 없음, 비표준 데이터 | 이미지, 음성, 자유 텍스트 |
암묵지와 형식지
암묵지(Tacit Knowledge): 개인의 경험, 직관, 통찰, 숙련 등을 통해 습득된 지식으로, 말이나 글로 명확히 표현하거나 문서화하기 어려운 지식입니다. 예를 들어, 자전거 타기, 악기 연주, 숙련된 장인의 기술 등이 이에 해당합니다. 암묵지는 주로 관찰, 체험, 모방을 통해 전달됩니다.
형식지(Explicit Knowledge): 문서, 매뉴얼, 데이터, 보고서 등과 같이 언어, 기호, 수치 등으로 명확히 표현되고 쉽게 전달, 공유, 저장이 가능한 지식입니다. 학교 교육, 기술 문서, 백서, 규정 등이 대표적인 예입니다. 형식지는 지식의 체계화, 전파, 축적에 유리합니다.
| 구분 | 암묵지 (Tacit Knowledge) | 형식지 (Explicit Knowledge) |
|---|---|---|
| 정의 | 개인의 경험과 직관에 기반한 내면화된 지식 | 문서화·정형화되어 외부로 표현 가능한 지식 |
| 표현 방식 | 언어나 문서로 표현 어려움 | 언어, 문서, 수식 등으로 명확하게 표현 가능 |
| 전파 방법 | 관찰, 실습, 경험, 모방 | 문서, 교육, 매뉴얼, 데이터베이스 |
| 예시 | 자전거 타기, 요리 실력, 장인의 기술 | 매뉴얼, 논문, 교육자료, 규정 문서 |
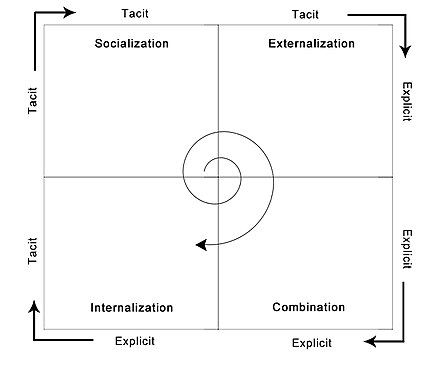
암묵지와 형식지의 상호작용: SECI 모델
지식은 단순히 저장되는 것이 아니라 암묵지(Tacit Knowledge)와 형식지(Explicit Knowledge) 간의 상호작용을 통해 지속적으로 창출되고 전파됩니다. 이 과정을 설명하는 대표적인 이론이 바로 SECI 모델로, 다음의 4단계로 구성됩니다:
-
공통화(Socialization): 말이나 문자 없이, 경험을 통한 직접적인 상호작용으로 암묵지가 암묵지로 전파되는 단계입니다. 주로 현장 실습, 관찰, 따라 하기(모방), 멘토링, 비언어적 시연 등을 통해 지식이 전수되며, 개인 간 공감과 체험 공유가 중요한 매개 역할을 합니다. 이 과정은 특히 문서화가 어려운 직무 노하우나 감각적인 숙련 지식의 전달에 효과적입니다.
-
표출화(Externalization): 개인이 보유한 암묵지를 언어, 기호, 수식, 이미지, 도표 등 명시적인 표현 수단을 활용하여 형식지로 전환하는 단계입니다. 이 과정은 지식의 체계화와 확산을 가능하게 하며, 브레인스토밍, 회의록 정리, 업무 매뉴얼 작성, 업무 프로세스 정의 등에서 활용됩니다. 창의성과 표현 능력이 핵심 역할을 하며, 조직 내 집단지성 기반 지식 자산화의 시발점이 됩니다.
-
연결화(Combination): 여러 출처에서 생성된 형식지들을 분류, 비교, 통합, 재구성하여 새로운 형식지로 가공하는 단계입니다. 주로 데이터베이스 구축, 통계 분석, 보고서 작성, 매뉴얼 개선, 지식 맵 개발 등의 형태로 나타나며, ICT 시스템이나 분석 도구를 통한 정보 정제와 연결이 필수적입니다. 이 단계는 조직 전체 지식 자산의 확장과 고도화에 기여합니다.
-
내면화(Internalization): 형식지로 정리된 정보나 지식을 학습, 실습, 체험 등을 통해 개인이 자신의 암묵지로 흡수·체화하는 단계입니다. 이는 이론적 지식이 직무 경험을 통해 노하우로 전환되는 것을 의미하며, 교육훈련, 자격증 취득, 프로젝트 참여 등을 통해 이뤄집니다. 내면화된 지식은 이후 다른 이들에게 공통화를 통해 전파될 수 있어, SECI의 순환을 가능하게 합니다.
이 이론은 일본의 노나카 이쿠지(Nonaka Ikujiro)로 교수가 제안한 대표적인 지식경영 이론이며, 데이터 기반 업무와 분석 프로젝트에서도 유용하게 적용됩니다.
SECI 순환 구조
이 네 가지 과정은 순환적이며, 조직 내에서 지식의 나선적 확산(spiral evolution)을 이끌어냅니다.
즉, 공통화 → 표출화 → 연결화 → 내면화 단계를 거치며 지식이 개인에서 조직으로, 다시 사회 전반으로 확장됩니다.
2. 데이터와 정보의 관계
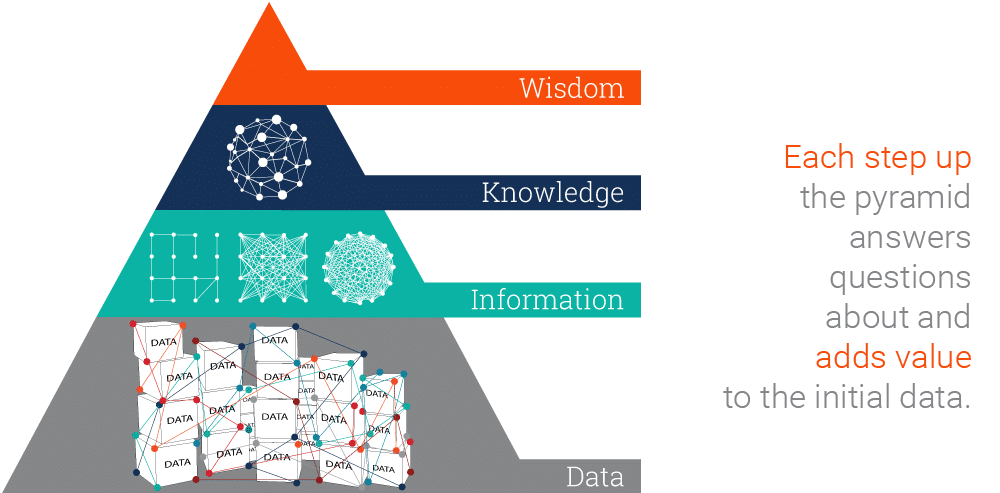
DIKW 피라미드
DIKW 피라미드 (Data, Information, Knowledge, Wisdom hierarchy):
DIKW 피라미드는 데이터를 가공하고 분석하여 정보, 지식, 그리고 최종적으로 지혜를 얻는 과정을 단계별로 나타내는 모델입니다. 각 단계는 다음과 같이 정의됩니다.
데이터 (Data): 존재 형식을 불문하고, 타 데이터와의 상관관계가 없는 가공하기 전의 순수한 수치나 기호입니다. 개별 데이터 자체로는 의미가 중요하지 않은 객관적인 사실입니다.
- 예시: 온도 센서의 측정값, 고객의 구매 기록, 웹사이트 방문 로그 등
정보 (Information): 데이터의 가공 및 상관관계 간 이해를 통해 패턴을 인식하고 그 의미를 부여한 데이터입니다. 데이터의 가공, 처리와 데이터 간 연관관계 속에서 의미가 도출된 것입니다.
- 예시: 특정 시간대의 평균 온도, 고객의 구매 패턴 분석, 웹사이트 방문자의 페이지별 체류 시간 등
지식 (Knowledge): 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물입니다. 데이터를 통해 도출된 다양한 정보를 구조화하여 유의미한 정보를 분류하고, 개인적 경험과 결합시켜 고유 지식으로 내재화한 것입니다.
- 예시: 과거 온도 변화 패턴을 기반으로 한 미래 온도 예측, 고객의 구매 패턴을 활용한 맞춤형 상품 추천, 웹사이트 방문자의 행동 패턴을 분석하여 사용자 경험 개선 전략 수립 등
지혜 (Wisdom): 개인에게 가장 깊숙이 내재되어 있으며 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적인 아이디어입니다. 지식의 축적과 아이디어가 결합된 창의적 산물입니다.
- 예시: 기후 변화에 대한 깊은 이해를 바탕으로 지속 가능한 에너지 솔루션 개발, 고객의 심층적인 니즈를 파악하여 혁신적인 제품 또는 서비스 개발, 웹사이트 사용자 행동 패턴 분석을 통해 새로운 온라인 마케팅 전략 수립 등
출처: ontotext - What Is the Data, Information, Knowledge, Wisdom (DIKW) Pyramid?
데이터에 관한 상식
비트(bit): ‘0’과 ‘1’의 두 가지 값으로 신호를 나타내는 최소 단위미여, 이진수를 뜻하는 ‘binary digit’의 약자입니다.
바이트(byte): 8개의 비트로 구성된 데이터의 양을 나타내는 단위이며, 1바이트로는 숫자와 영어의 한글자를 표현할 수 있스빈다. 한글은 한 글자가 2바이트(byte) 크기를 갖습니다.
데이터 단위
1byte = 8bit
1KB = 1024byte
1MB = 1024KB
1기가바이트(GB) -> 1테라바이트(TB) -> 1페타바이트(PB) -> 1엑사바이트(EB) -> 1제타바이트(ZB) -> 1요타바이트(YB)